
In August 2022, I wrote a blog about the current state of zkEVMs: Ground Up Guide to zkEVM, EVM Compatibility and Rollups. The same week, Vitalik put out his own blog post on the Different Types of zkEVMs which established the Type 1, Type 2 taxonomy which is now commonly used to describe zkEVMs - tough competition!
In that blog, I made a prediction:
…it’s also appropriate to be sober-minded about the current readiness of smart contract rollups. Every team has a strong incentive to market themselves as “just about to take over the world” — but there will be no “production-grade” smart contract rollups on Ethereum until the end of 2022 at the earliest, and many of these teams will not be ready until deep into 2023.
Well, we’re now “deep into 2023” - what’s the status of zkEVM development and adoption? It’s been a big year for zkEVMs on many fronts:
- Polygon zkEVM, Linea and Scroll all launched!
- Immutable announced that our next rollup would be Immutable zkEVM
- Polygon announced their plan to upgrade Polygon PoS to a zkEVM Validium
- Optimism suggested their intent to support running OP Stack chains as zkEVMs
However, the numbers speak for themselves:

Put simply, zkEVM development is progressing, but no zkEVM currently has huge adoption compared to existing blockchains. The purpose of this blog is to answer the obvious question - how are the various zkEVM projects progressing, and what will it take to generate the traction we want to see?
First, let’s start with a quick refresher on Vitalik’s “zkEVM types”, which are helpful in describing zkEVM projects:

This looks complex, but is actually fairly simple to understand. Everyone’s initial mental model for a zkEVM is just taking an existing Ethereum execution client (e.g. Geth, Nethermind, Erigon), generating zk-proofs of its execution trace, and using these proofs to secure an L1 <> L2 message bridge. However, the EVM wasn’t designed with zk-proving in mind, and this approach is highly inefficient (e.g. Ethereum’s keccak hash function is very expensive). We therefore have a few options:
- Type 1 - Deal with it, my users/I will pay. There are two major advantages here: you can use Type 1 provers with existing blockchains, and you won’t need to maintain your own Ethereum client (development costs can be just as expensive as proving costs), though you will have to keep your execution clients updated.
- Type 2 - Don’t touch the “application layer” (e.g. no changes to opcode costs/implementations), but modify the nodes on your chain to have a more prover-friendly internal structure (e.g. using a Sparse Merkle Tree for your state). The big downside of this approach is that you’ll need to maintain a permanently forked Ethereum client. Given the fact that Ethereum already struggles to maintain multiple production grade clients, this is a non-trivial task and will require a team of specialist blockchain engineers.
- Type 3 - Do everything in Type 2, and also modify the EVM to get rid of the hardest bits to prove (e.g. some of the rarely used precompiles) and potentially increase opcode costs for prover-intensive operations. This is the fastest way to get your prover to market, but you will need to make all the client changes above and experience areas of incompatibility with existing Ethereum applications and tools (e.g. any contract which uses those precompiles will break).
- Type 4 - Create a custom VM which is specifically designed for efficient zk proving, and create a custom client for running that VM. This will make proving costs much cheaper, but you’ll need to build a large ecosystem of tools and infrastructure to support your custom VM/client. You may be able to offer some form of transpilation of Solidity code, but developers will probably have to make substantial changes to their existing contracts and tools to deploy on your chain. In my view, most Type 4 rollups are not really zkEVMs - “smart contract zk-rollups” is probably a more accurate description.
This might be a little bit easier to understand in the form of a table:

At the end of 2023, almost every live project is a type 3 or type 4 rollup, for a very simple reason: they have been much faster to build (at the cost of compatibility and increased maintenance overhead)! Interestingly, almost every project which is currently a Type 3 is aiming to eventually become a Type 2 or Type 1 rollup to improve their compatibility with Ethereum and potentially remove the need to develop their own client software.
In last year’s blog I focused mainly on how each zkEVM team had designed their prover. This year, I want to cover the other important facets of each project’s approach, including things which are definitely not discussed frequently enough (e.g. the plan for each zkEVM’s execution client). For instance, many people think of L2s as “sequencer” and “prover”, when the standard zkEVM design actually looks more like this!

There are alternative sequencer designs (which we’ll discuss later), but most zkEVMs currently plan to run a separate blockchain as the L2 sequencer, with its own execution client (receives and executions transactions) and consensus client (reaches consensus on the order of transactions across all the L2 nodes).
Importantly, modifying the standard Ethereum clients to create your custom chain comes at a cost. Every Ethereum client change (and particularly every hard fork) will be a governance decision point for all zKEVM teams. The more you customise, the more difficult it will be for you to adopt upstream changes. Over time, this can easily lead to drift - zkEVMs that matched Ethereum at some point in time will become rapidly desynced.
The State of zkEVM Projects
So where are the projects we covered last year?
Polygon zkEVM (and Polygon CDK-Based Chains)
Polygon zkEVM launched on mainnet in March 2023 and has so far processed close to 10m transactions. It is currently Type 3 (see Ethereum differences), and aims to become Type 2 at some point in 2024.
Of course, as a Type 2/3, Polygon zkEVM requires its own custom client implementation. Polygon has chosen to build their own client from scratch (zkevm-node) for compatibility, but this client is new, has suffered outages, and is missing many of the features found in the standard Ethereum clients.
To offset this, Polygon has partnered with gateway.fm to modify Erigon (formerly turbo-geth) to support the changes needed for a Type 2/3 prover. This will give Polygon zkEVM a more stable base layer and improved performance, though maintaining compatibility with upstream Erigon will still pose an ongoing challenge.
A number of teams have also announced that they will be building zkEVMs using Polygon Chain Development Kit (CDK), including Astar, OKX and Palm Network. Polygon CDK’s vision is to allow developers to build their own custom chains by composing different clients, provers and data availability solutions according to your needs (i.e. a built-your-own-zkevm toolkit). Today, CDK supports one client implementation (zkevm-node) and one prover (Polygon zkEVM). In future, the Polygon team plans to add additional client implementations (e.g. Type-2-Erigon) and provers (e.g. Polygon Zero) to CDK.

This means that you can deploy your own version of Polygon zkEVM today! However, any team that deploys using zkevm-node is likely to need to migrate to another client in future, so you may want to hold off until this is ready.
We should also note that Polygon is planning to upgrade Polygon PoS (one of the largest and most successful blockchains in the world) to a zkEVM with off-chain data, though the timeline is not yet locked in.
Scroll
2023 has seen the launch of two Scroll testnets and a mainnet (in October) - a massive year of building! Scroll is currently a Type 3 zkEVM, and have previously stated their intention to move to a Type 1/2 in future, though the timeline is not yet clear. They maintain a list of differences with Ethereum, including several unimplemented precompiles and some minor state modifications. Scroll’s client is a fork of Geth v1.10.13, and they are currently operating in single sequencer mode. It’s worth noting that some parts of Scroll’s execution client are already two years behind upstream Ethereum (though they have cherry-picked the Shanghai execution client EIPs to reduce application-layer deviation). This will not cause any immediate disruption to the chain, but is indicative of the governance challenges many projects will face in determining how close to remain to upstream Ethereum long term, and how much engineering effort will be required to continually close this gap.
Immutable zkEVM
Disclaimer: I’m the co-founder/CTO of Immutable.
Immutable zkEVM has had a public testnet since July, and is planning to launch mainnet in January. Immutable zkEVM uses a version of the standard go-ethereum client which has been customised for our core domain (gaming). Interestingly, Immutable zkEVM is the only domain-specific zkEVM currently on this list, even though the ability for L2s to be tailored to the requirements of a particular area while retaining Ethereum security is one of their main attractions. For example, Immutable zkEVM is content to use validium data availability to reduce costs and has chosen a single-block finality PoSBFT design to provide near-instant confirmations, decisions which might not suit a general purpose chain. Additionally, there may be network effects if a substantial number of games and gaming users flock to this chain - we expect to see more domain-specific L2s in future.
However, the chain will launch without prover support. This is because Immutable zkEVM plans to adopt the Type 1 Polygon Zero prover when it becomes available and cost efficient. The only way for Immutable to launch with a Type 3 would be with substantial client modification, which we are reluctant to do given the implications for client drift away from Ethereum. Today, Polygon Zero is based on Plonky-2, with Plonky-3 in active development and estimated to provide a performance improvement of around an order of magnitude when it is production grade in mid-late 2024. This will give Polygon two independent provers (Polygon Zero and Polygon zkEVM) which developers will be able to choose between for use in their CDK-based chains.
Linea
Linea launched their mainnet back in August, and are on a similar path to Polygon/Scroll: begin with a Type 3 rollup and move to a Type 1 or 2 over time. Linea currently contains only a few differences from Ethereum London, described in this table.
Linea is using their own modified version of Geth which they have named “zkGeth”. Concerningly, the source code for this client is not publicly available, and neither is the prover - there is no way for users to verify that either are performing as expected. They are planning to open source all these components as part of their well-documented decentralisation roadmap. Linea’s documentation indicates that they plan to switch from “zkGeth” to linea-besu, a modification of the Consensys-developed Besu client. Over the medium term, the Linea team plans to merge linea-besu and regular besu and rely on Besu’s plugin system (e.g. https://github.com/Consensys/besu-shomei-plugin) to make the state modifications necessary to be a Type 2 zkEVM.
Taiko
Taiko is up to their fifth testnet, with plans to be live on mainnet by next year. Taiko is developing their own zk prover closely based on the PSE implementation (similar to Scroll). Interestingly, Taiko is the only team in this article which is currently contemplating a design other than a single sequencer progressively decentralizing into a L2 blockchain. Taiko’s design is based on the concept of a Based Rollup as described by Justin Drake - rather than having a permissioned validator set, anyone will be capable of submitting batches and proofs to Ethereum L1. This implementation means that the rollup effectively fully delegates sequencing to Ethereum L1, allowing it to automatically inherit the liveness and decentralization of Ethereum L1. However, it comes with an important disadvantage: there will be no “fast finality” confirmations offered by an L2 sequencer, meaning users can expect longer confirmation times for each transaction. Justin Drake has proposed “Based preconfirmations” to provide probabilistic confirmations with a latency of only 100ms, though it is not close to production and the introduction of a separate system of “preconf promises” and “preconf tips” is likely to have implications for existing Ethereum tooling. This is an active area of research!
Taiko has stated their intention to be a Type 1 zkEVM from the outset. They argue the compatibility differences introduced by other zkEVMs will be much worse than higher proof generation costs, which will come down anyway as the technology improves. Taiko’s client implementation is interesting - the core “execution client” is a modified Geth v1.13 (taiko-geth). However, they are also maintaining their own “consensus client” (taiko-client), which handles communication with L1 and monitors the based sequencing process. By separating the L1 communication logic into the consensus client, they can stay close to upstream Ethereum execution clients.

zkSync Era
zkSync Era was launched in March 2023, and has been successful so far, with rumours around a forthcoming airdrop propelling its TVL to more than $500m. zkSync is a Type 4 zkEVM, as they are proving their own custom VM (eraVM) rather than attempting to a modified EVM directly. They are aiming to be “language level compatible” with Ethereum, and have provided a direct compiler from Solidity code to their custom VM. They have made substantial changes to the implementation of many critical EVM opcodes, as well as several changes to the compilation process, meaning developers often need to modify their contracts or deployment scripts for deployment on zkSync Era.
zkSync Era has its own custom client, allowing them to implement non-EVM features like native account abstraction. In July 2023, they upgraded their prover to “Boojum”, a STARK proof system which is then wrapped with a SNARK for on-chain verification, similar to Polygon zkEVM. zkSync Era requires fully on-chain data, but they plan to introduce “zkPorter” in future, which will allow users to choose between different data availability modes at different price points, similar to the Volition model proposed by StarkWare.

StarkNet
StarkNet is one of the most ambitious projects in the Ethereum ecosystem: they are building a Type 4 rollup and ecosystem from scratch, including a new VM (CairoVM), a new programming language (Cairo), a new prover (Stone) and new clients (Pathfinder, Papyrus, Juno). StarkNet progressively opened up over 2021 and 2022, and now has more than $150m in TVL, processing 10m+ transactions each month.
Building this new ecosystem from scratch is extremely challenging, but provides the opportunity for fundamental innovations in areas where the EVM has struggled (e.g. native account abstraction) and substantial performance improvements. Large parts of this toolchain have been tested extensively through StarkEx-based projects like Immutable X, dydx v3 and Sorare, which have been live since 2020 and have been widely adopted.
Initially, the StarkNet ecosystem explored language-level compatibility through projects like the Warp Solidity → Cairo transpiler that I mentioned last year. However, Warp has now been sunset, and the StarkNet ecosystem has instead resolved to fully commit to the new CAIRO toolset rather than aiming for any type of Solidity backwards compatibility. Now, they face the same challenge as non-EVM ecosystems like Solana or Sui - can you get a critical mass of developers to adopt your new tooling, or will the ubiquity of the EVM win out?
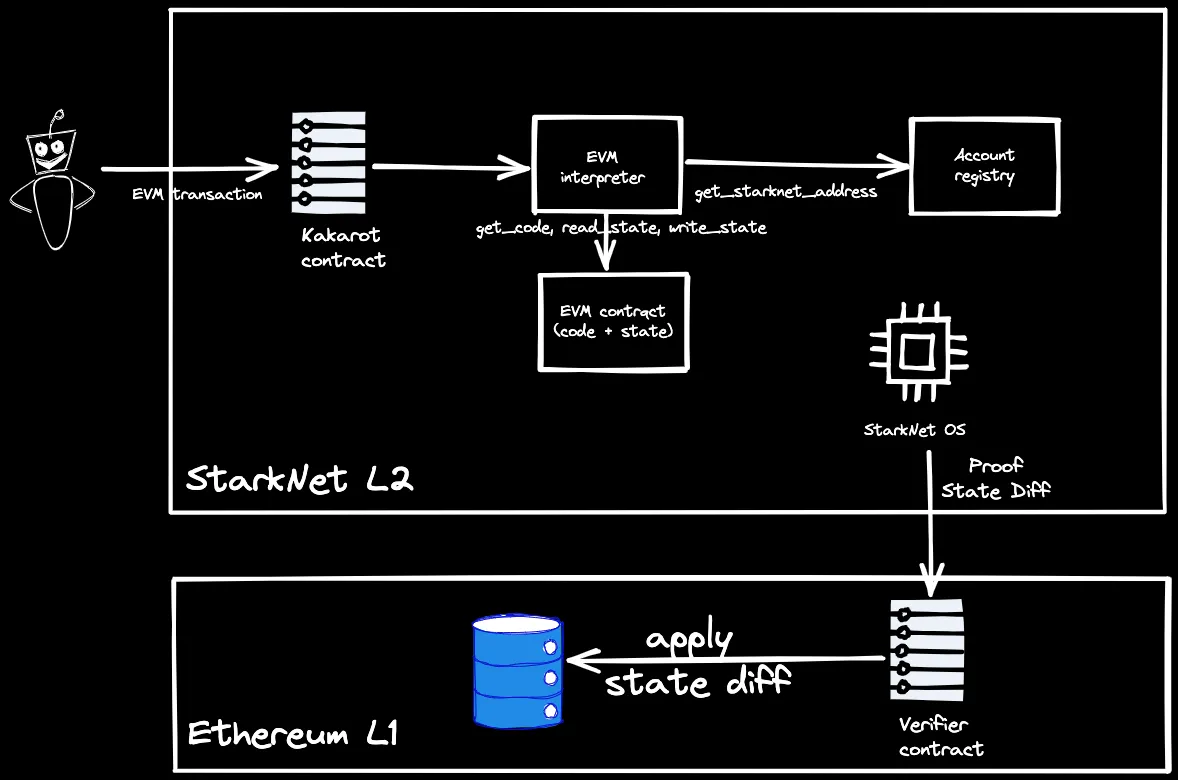
The exception to this is the work being done by the team at Kakarot, who are building a Type 2.5 EVM in CAIRO which will exist as a set of contracts on StarkNet. Via Kakarot, users will be able to deploy and interact with EVM contracts which have their code/state on StarkNet, allowing users to benefit from StarkNet’s performance while retaining EVM compatibility. As the underlying execution environment will still be StarkNet, this will sacrifice Ethereum tooling compatibility - but this may be an acceptable tradeoff for some projects. Kakarot is not yet production-grade, and the performance and tooling compatibility implications of this layered approach are not yet clear, but it’s an exciting attempt to bridge the gap between the various zkEVM types and indicates just how early we are in exploring the design space.
Bonus: Optimism
For obvious reasons, Optimism is generally regarded as an exclusively optimistic-rollup-focused team. However, they have repeatedly stated their intention to support zk-proving as an option in future, and have been in active discussions with several teams who have offered contributions. Exciting zk-ecosystem projects like zeth are now supporting Optimism blocks. However, we haven’t seen any formal timeline or design - perhaps there will be an exciting update in next year’s zkEVM review!
As you can see, there is a huge diversity of approach between the various zkEVM teams. Even rollups that share a type are often adopting fundamentally different designs with their prover, client and sequencing mechanisms.

There’s another very important way to compare these nascent zkEVMs - their actual configuration! Generally speaking, the architecture of each chain’s client and prover is more interesting to analyse, because it speaks to fundamental design decisions rather than application-level configuration which can easily be changed. However, if you’re an application developer, configuration details absolutely matter, so make sure you research each zkEVM’s block time, block gas limit, proof publication frequency, sequencer consensus mechanism and anything else which might impact your application’s UX!
The sum total of the above: a huge amount of development has taken place in 2023, across a wide variety of teams. So, if development is progressing, do we just need to wait? What do we still need to solve to see zkEVMs have substantial traction?
What are the unsolved problems in zkEVM development?
First, there is no standardised interface between clients and provers. Currently, every prover is only compatible with the client they were initially built with. You won’t be able to use Polygon zkEVM’s prover with any other Type 2/3 client. Ideally, any new prover or client should be compatible with as many existing provers/clients as possible. An EIP (e.g. the draft proposed here) which encourages the various zkEVM teams to conform to a single interface is an important future step.
Understandably, most teams are currently prioritizing improving their own implementations rather than seeking compatibility with others. This is probably acceptable for now, but eventually we will want L2-sequenced zkEVMs in particular to use multi-client/prover setups to reduce the risk of major bugs. Additionally, standardizing the implementation of the “classic” type 2 features (e.g. Sparse Merkle Tree, Poseidon hash function instead of keccak) may help multiple provers use the same or similar clients. Reducing the number of “almost geth” clients will be a huge win for the ecosystem! A standardisation initiative named “RollCall” has been proposed, alongside a series of Rollup Improvement Proposals (RIPs 💀), though it is unclear how much traction this has currently.
Second, these zkEVMs are almost exclusively single sequencer, which poses challenges for the decentralisation and security of these rollups. It is important to note that the prover acts only to ensure that the L1 <> L2 bridge is secure. Any external systems (such as CEXs) which rely on the L2 pre-confirmations are putting significant funds at risk by relying exclusively on the single sequencer - for many L2s today, a damaging hack is only one compromised sequencer key away. However, once you decentralise the sequencer, another set of challenges emerge (as you see from the Taiko description above!). Should you need to provide a zk-proof to L1 that L2 consensus was reached? What about liveness issues? What about MEV? Most single sequencer rollups are currently not exploiting MEV for brand/reputation/chain confidence reasons, but this may change in future.
Third, there is no standard framework for measuring zkEVM performance and cost. A lot of this article is focused on comparing the potential performance implications of various zkEVM designs, but currently very few zkEVM teams have published any actual performance specifications or tests. There are several separate components to “zkEVM cost”:
- the cloud compute cost of generating proofs (impacted by circuit efficiency)
- the L1 cost of proof verification
- the cost of data availability
- the cost of sending messages from Lx <> Ly
I should be able to create standardised tests for these areas and tabulate the results to help builders make more informed decisions - currently this is impossible. There’s nuance here: some prover implementations will be better than others at some types of transactions, some cost will depend on usage due to being able to amortise transaction costs over a batch. How these costs should be surfaced to users is also a big area of uncertainty (e.g. Immutable zkEVM is planning to cover publication costs for users in most cases, while Scroll has a complex L1 + L2 fee setup to ensure each transaction is unit profitable). Additionally, many zkEVMs are likely to grapple with performance issues related to state growth - expanding Ethereum blockspace is not free! All of the above needs to be much more measurable/comparable than it is today.
Fourth, exit games remain poorly understood and ill-defined for most smart contract rollups. Self-custody is well defined on application-specific rollups like Immutable X - any asset you deposit into the L1 bridge should be retrievable even if the sequencer is fully offline or fully malicious. This is often referred to as an “escape hatch”. But what does this mean in the context of a smart contract rollup? What if your ETH is staked in a contract and shouldn’t be available anyway? Is it all about censorship resistance - do we need to guarantee the ability to force transactions? What level of data availability is acceptable for zkEVMs used for different purposes (e.g. gaming assets vs. DeFi)? We need consistent frameworks to communicate the actual failure conditions for users - L2 Beat has made a good start on this!
Fifth, the relationship between zkEVMs and Ethereum L1 is still unclear. Between the first draft of this post and its final release, I was once again ninja’d by Vitalik releasing a blog post reflecting on “enshrined zkEVMs”. The TL;DR is that the Ethereum client layer could have “enshrined” zk prover implementations which could be used to verify the execution of EVM blocks submitted from other sources (e.g. L2s). This could avoid each L2 zkEVM having to keep their zkEVM provers up to date (big win!) - they could piggy back off the work of other teams, including the core Ethereum client teams as a fully SNARKed Ethereum becomes a reality. So, should I read proposals for “enshrined zkEVMs” as a deviation from Ethereum’s L2-focused scaling roadmap, bringing L2-captured value back into the mothership?
Well, not really. L2s would still need their own sequencers to provide fast confirmations (critical in domains like gaming), and Vitalik’s proposed design would only support zkEVMs with fully on-chain data. Most L2s would almost certainly wish to preserve independence for monetization reasons, pointing to an important tradeoff for the Ethereum ecosystem. L2s are critical for scaling Ethereum block space - but their incentives (and BD teams) may not always be aligned with Ethereum.
Lastly, multiple zkEVMs will continue the fragmentation of users and liquidity, producing a poor user experience. Today, each additional Ethereum L2 continues to fragment state and liquidity - if you have 2 ETH on Arbitrum, that ETH is challenging to access on any other L2. In my view, this is by far the best argument for monolithic blockchains, where composability is vastly improved and users don’t have to juggle balances across multiple chains. With the current proliferation of “L2 toolkits” (e.g. Polygon CDK, Arbitrum Orbit, OP Stack), it has never been easier to spin up a chain, but this comes at the cost of even more fragmentation.
For this model of multiple L2s to be successful long term, we will need to abstract individual chains and balances away from users in most cases. This is one of the strongest arguments for validity proofs over fraud proofs - instant proof verification for rapid bridging between chains. However, even with a strong bridging/interoperability framework, there are still a huge number of user experience challenges to solve. At Immutable, our plan is to tackle this head on through our vertical integration and Immutable Passport at the wallet layer. More to come on this soon!
Summary
2023 has been simultaneously a banner year for zkEVMs in terms of development progress and a year of preparation when it comes to actual adoption. 2024 will be the first year where Type 1 and 2 zkEVMs are actually ready for production usage, but we realistically won’t have them until Q3/Q4 at the earliest - and we still need to solve many performance problems to get there!
I do want to make it very clear that the main problem for zkEVMs to solve in 2024 is not a technology problem (though we clearly still have some), but a value problem - can we create exciting applications for users on this next generation of L2s? We need both amazing protocol developers and amazing application developers!
Shameless plug: if you’d like to work at the intersection between crafting the future of zkEVM tech and actually driving application adoption by helping developers build mainstream-ready web3 games, we’re hiring at Immutable!
This article was originally published by Alex Connolly, Immutable CTO and Co-Founder, at alexconnolly.xyz






